

AI model tokens are becoming the new nightmare for software engineers. As you progress and understand how token consumption hits your pocket, and consequently affects your project's development, you start looking for alternatives.
In my case, I started a few projects using models with a lower cost per token, which usually means lower capacity or speed. In some scenarios, I managed to complete everything using only these models. However, in other projects, I had to resort to more advanced models, and that's when token consumption increased significantly.
To illustrate, we are currently in early April, and my premium token requests have already exceeded 50% of the monthly limit. Clearly, maintaining this pace is not sustainable.
Recently, I discovered a library called RTK, developed in Rust. It works by intercepting terminal output and filtering out redundant content before it is sent to the model, helping to reduce the volume of tokens consumed.
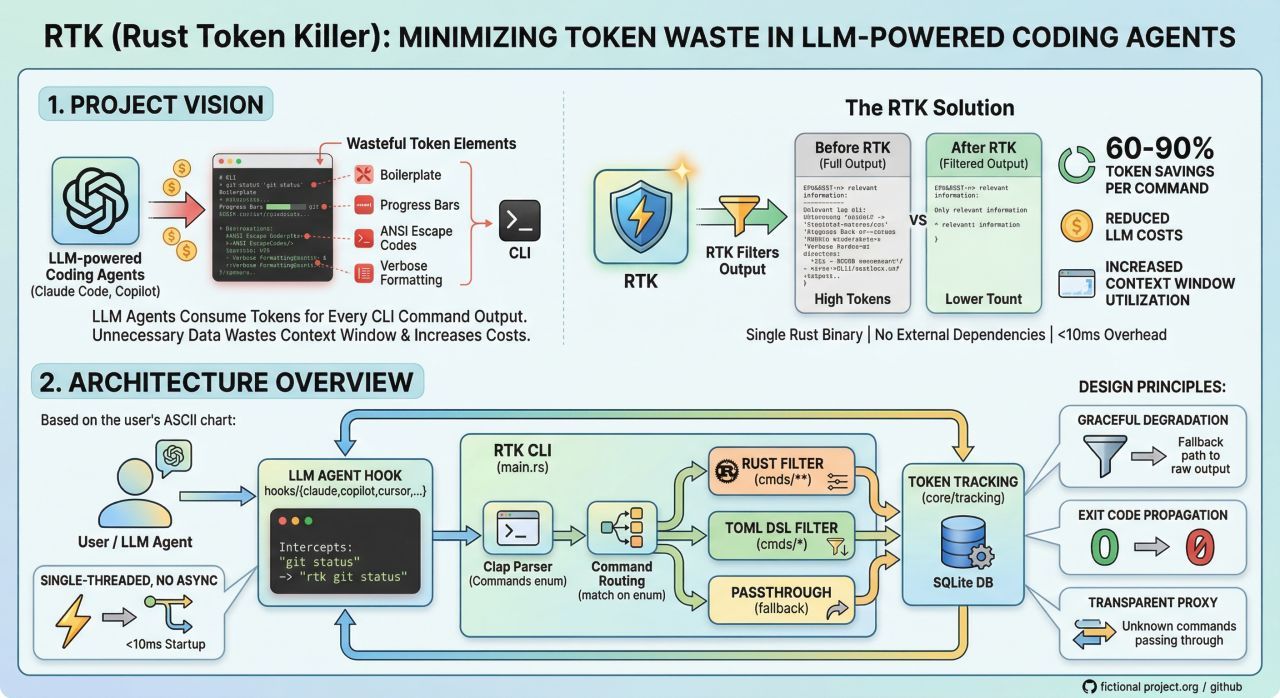
RTK isn't a silver bullet, but it has already brought relevant gains by decreasing token consumption in routine tasks that an agent performs during feature development, refactoring, and documentation generation.
Some users report a significant reduction in token usage during sessions of approximately 30 minutes. Without RTK, a session might consume around 120,000 tokens with the tool, that number can drop to somewhere around 25,000 tokens.
Installation on macOS is simple:
brew install rtk
rtk init --global
For engineers using tools like Claude Code, Cursor, or custom workflows with AI agents, RTK can act as an interesting intermediary layer, helping the model focus more on logic and less on unnecessary noise.
Tools like RTK help, but the greatest savings still come from workflow changes, primarily in how we use context and iterate with it.
See you in the next post. 👋🏻🧑🏻💻